

Running an advanced technical SEO audit is vital for search engine optimization as it unveils intricate site issues impacting search visibility and performance.
But advanced technical SEO is one of the most guarded techniques among SEOs, with most guides only touching on the basics.
In this blog, I'll show you how to take your techniques from routine to advanced, drawing from the expertise of top SEO and digital marketing practitioners, with whom we've collaborated with for years.
I'll also review how to utilize our enterprise SEO platform to address indexation, accessibility, search intent, and crawl errors. Plus, I'll go over more advanced techniques to help you develop new skills that will enhance your technical audits.
Table of Contents:
(Note, for this walk-through, I’m going to use our suite of technical SEO capabilities within seoClarity.)

Free Downloadable SEO Audit Checklist
This guide revolves around completing advanced technical site audits, but if you're looking to get started with your first site audit or you're new to site audits altogether, I suggest you download our free, 16-step SEO audit checklist. It comes complete with easy-to-follow, bucketed tasks for SEOs to follow!

#1. Indexation
As Google's index faces limits due to the rapid influx of AI-generated content, auditing your crawl budget is more important than ever. Below, we'll dive into the different types of crawls you can set up to monitor your site and ensure your most important pages get indexed.
Setting Up Recurring Crawls
Websites rarely remain static for long - new pages are added frequently, technical functionalities change, and other updates increase the potential for new errors and issues.
Recurring crawls help you get ahead of errors and monitor progress, which also creates a baseline for reporting organic traffic to executive teams (and monitoring technical errors).
I always recommend our clients decide on a flat audit schedule before diving into audit data so they can monitor progress before and after each professional SEO audit.
If your organization adds new features or updates the site regularly, set up the audit to coincide with the development schedule. Otherwise, schedule crawls to happen weekly, bi-weekly, or monthly depending on your team's internal development change rate.
In our guide to crawling enterprise sites, we offer advice on things like crawl depth and parameters to avoid slowing down overall site speed.
First Crawl
The first crawl sets the benchmark for evaluating the effect of any changes you’ve made to your site.
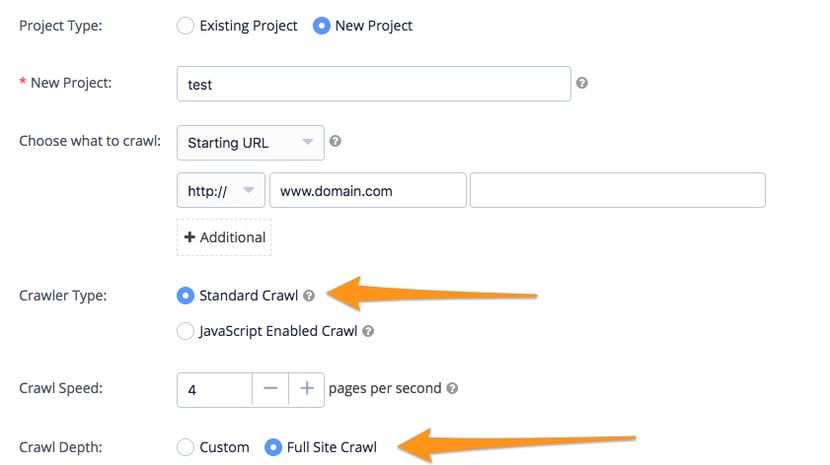
The benchmark data will also help you in these other ways:
- Demonstrating to your executive team the progress you’re making with improving the site
- Pinpointing ongoing development issues to forward to your perspective teams
- Allowing an initial performance benchmark so you can set up alerts to notify your team of any changes
XML Sitemap Crawls
Using an XML sitemap and submitting it to Google and Bing helps search engines find and index new pages on your site quickly.
When launching the crawler, schedule a separate audit to assess your XML sitemaps and ensure that all the URLs contained within them are fresh, relevant, and up-to-date. Doing so helps search engines identify and index your most important pages.
If you find server errors (not 2xx status), this process allows you to quickly identify what those errors are.
Identifying errors in your XML sitemaps can assist in discovering any roadblocks in design, internal linking, and other errors that need to be resolved.

In particular, focus on identifying these issues in the sitemap crawl:
- Pages with status URLs other than 200
- Canonical mismatch URLs
- An inconsistent number of pages crawled and the number of pages on the site.
- Indexation issues, particularly the number of pages on the sitemap vs. the number of pages in Google’s index.
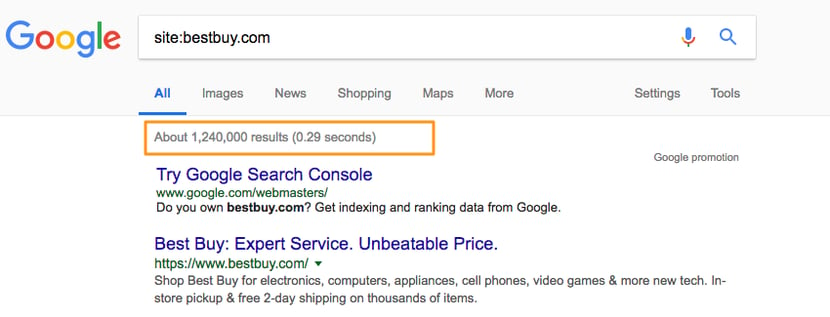
When it comes to finding indexation issues, you could previously get a pretty accurate number utilizing a “site:domain” search (see the SERP image below). But, over the years, Google began hiding the actual amount of indexed pages.
One solution is to review the amount of indexed URLs provided with Google's Index Status Report. Advanced users can also reference this article written by Paul Shapiro on how to utilize R scripting language to get a more accurate read on how much of your site is currently indexed.
You can also utilize Bot Clarity combined data in this reporting.
Diagnosis Crawls
At seoClarity, we also have the capability to crawl your site for specific, more advanced technical issues.
Diagnosis crawls help identify issues such as content imports from external sources and third-party resources that fail to load or are inaccessible.
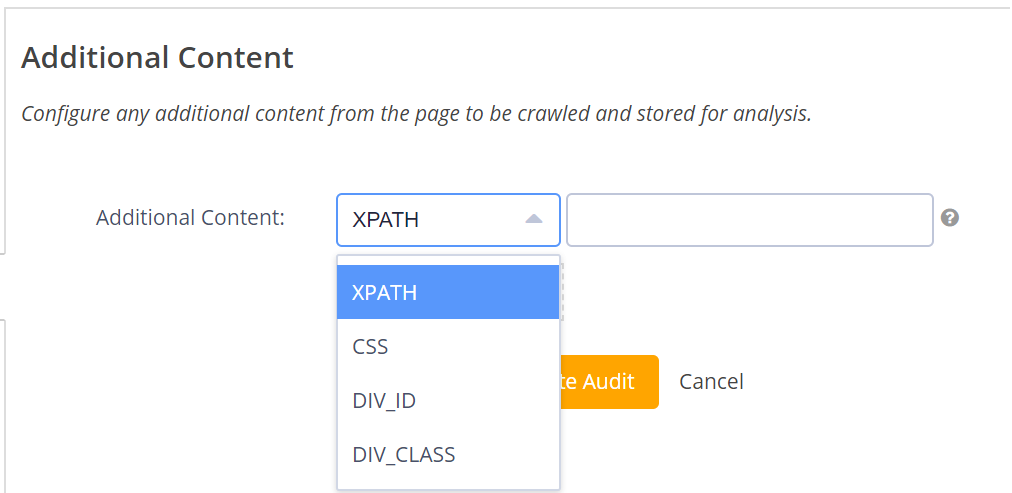
seoClarity's built-in crawler offers XPATH, CSS, DIV_ID, and DIV_CLASS crawling options, aiding in pinpointing specific errors. For instance, a client rolled out new CDN-loaded content across their site, which caused ranking issues due to an identifiable <div> tag. Using a crawl, we determined affected pages with the tag, comparing them to those without it.
The key to utilizing the crawler is to ensure that the Development team also follows these best practices and identifies attributes as new items are added to the site. As you perform an audit, zero in on the items that have been launched to ensure they follow best practices.
For example, if your site or page is not being indexed, the most common culprit is the use of a meta robots tag on a page or the improper use of disallow in the robots.txt file.
Our crawler has a setting that allows it to obey the robots.txt file and find out if the pages are blocked by mistake.
If a page or directory on the site is disallowed, it will appear after Disallow: in the robots file. For example, if I have disallowed my landing page folder (/lp/) from indexing using my robots file, this prevents any pages residing in that directory from being indexed by search engines.
We also collect the robots meta tag to identify the issue, like when a site has added a noindex tag to the page but is meant to be indexed.
For example, you can tell search engines that links on the entire page should not be followed which limits your crawl budget to your most important pages.
We have had clients un-index entire sections of their sites by adding a noindex tag to content. Having this ability to crawl and set up an alert helps clients make sure content doesn't accidentally get un-indexed.
Probably the two directives that are checked most often for SEOs are the appearance of the noindex/index and nofollow/follow. Index/follow, implied by default, indicates that search engine indexing robots should index the information on this page and that search engine indexing robots should follow links on this page.
Noindex/nofollow indicates that search engine robots should NOT index the information on the page and NOT follow links on this page.
Now that you have all of your baseline data and have utilized Clarity Audits to diagnose any issues, you'll want to assess your site's visibility.
#2. Assessing Visibility
One of the most important (and most challenging) SEO strategies is making sure your site and its content are accessible and deliver the best user experience possible — which, in turn, ensures search engine accessibility.
When crawlers find a webpage, Google’s systems render the content of the page, just as a browser does. Our software can imitate a Googlebot and analyze pages to identify issues that would prevent it from accessing or indexing pages.
If our crawlers cannot access your site, our team will identify the errors causing the block so that you can be certain those pages are accessible.
Search visibility changes over time. Using advanced ranking analysis in seoClarity, you can dive deeper into shifts in ranking factors over a specific time period. Integrate your analytics to have the complete picture in one centralized location.
Diagnose Pages
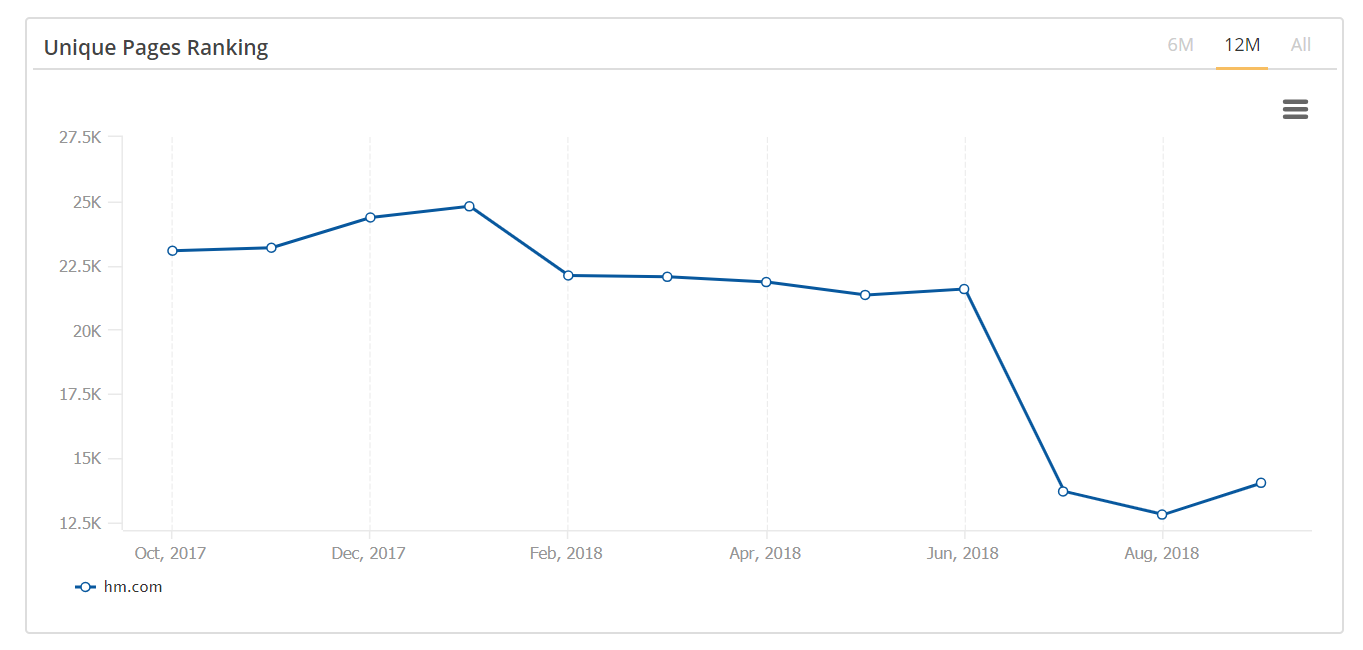
Advanced practitioners use seoClarity to diagnose accessibility and indexation issues on their sites.
The data set shows the number of ranking pages and any decreases in page rankings. You can also filter by a specific URL type to quickly identify which page type is being affected.
Error Pages
Next, search your site for pages that trigger error server codes or redirects and evaluate why. If possible, correct those redirects or fix server issues causing pages inaccessible.
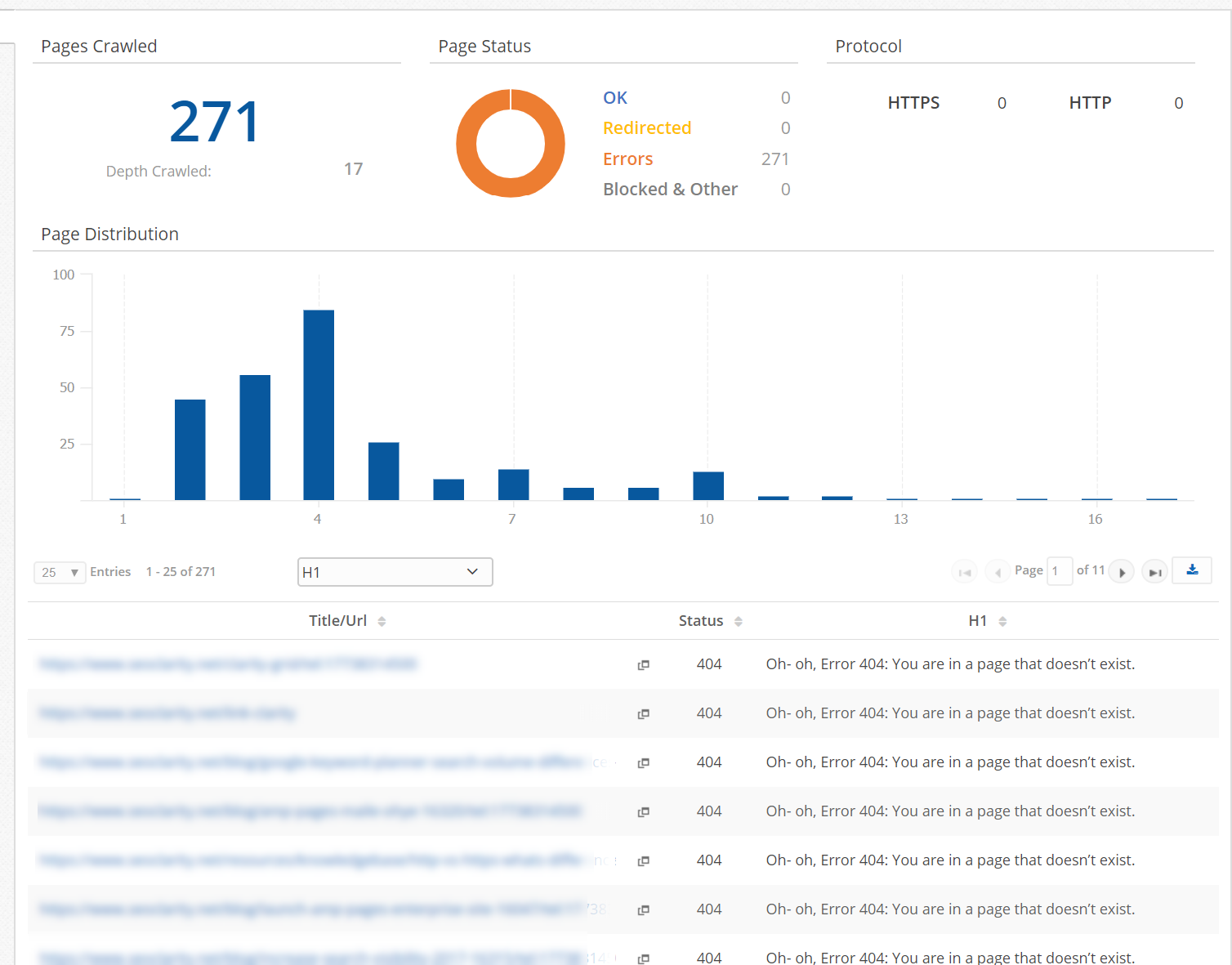
We recommend also reviewing our previous blog posts performing a site audit to identify additional areas to quickly monitor.
#3. Evaluating Search Intent
As Google searches become even more refined, focusing on search intent is increasingly important.
Advanced technical practitioners should aim to divide all their target keywords by user intent and create pages that specifically fulfill that purpose.
But manually evaluating the SERPs to determine the intent of a query isn't scalable.
seoClarity's AI SEO content writing tool, Content Fusion, allows you to check your pages and identify which ones are "Informational," "Transactional," "Navigational," or "Local" based searches.
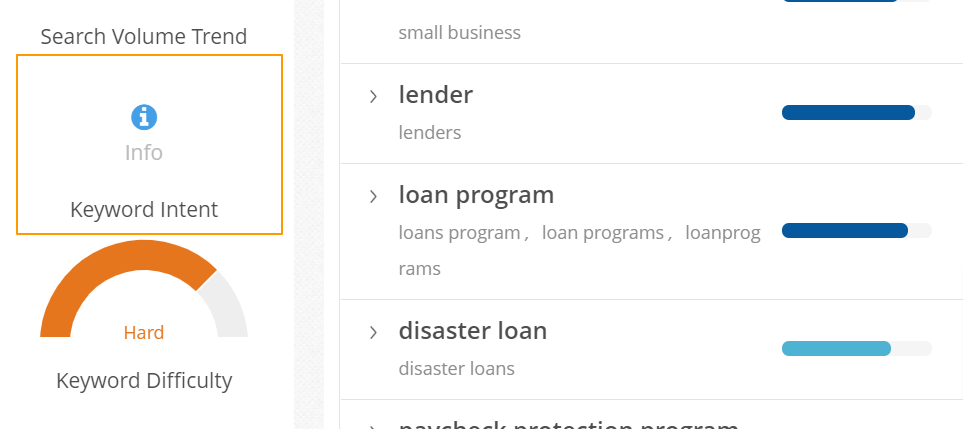
It allows you to create page tags and keyword tags based on intent, then isolate pages that need additional content versus pages that need to display product pages.
Once defined, zero in on optimizing the content around the keyword's particular search intent and quickly identify errors where the wrong URL is displaying for a particular search term.
#4. Eliminating Crawl Budget Issues
Search engine crawlers have a limited time to analyze your site which, as previously stated, may continue decreasing as Google must index a smaller percentage of web pages due to the influx of AI-generated content.
Any potential crawlability errors will waste that crawl budget and prevent them from accessing some of your content.
Devote part of your audit to eliminate crawler roadblocks and make the most of your available budget. seoClarity offers two distinct capabilities for this.
Bot Clarity monitors how search engine bots crawl your site in the following ways:
- If there are challenges to crawling your site, Google will store the URLs to revisit.
- According to our experience working with clients, Google will store and revisit URLs approximately 4-5 times to gather information on the URL.
- Bot Clarity allows you to see the frequency of visits to singular URLs or URLs by page type identifying an issue.
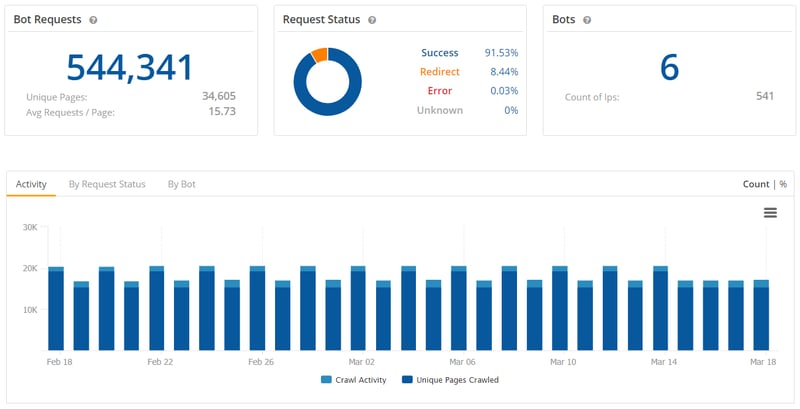
Similarly, Bot Clarity also allows you to identify spoof bot activity and block those crawlers from eating up your bandwidth.
Recommended Reading: SEO Crawl Budgets: Monitoring, Optimizing, and Staying Ahead
Clarity Audits can be used to imitate a particular bot and identify what issues specifically prevent them from accessing all sites within the crawl budget.
Some of the issues this crawl might reveal include:
- Broken internal links
- Long redirect chains
- API call outs
- Inaccessible content
- Page speed and load time issues
- Errors in robots.txt file blocking bots from accessing specific sections
#5. Internal Links
I’m often amazed at how little attention SEOs give internal links.
Internal links offer an incredible opportunity to boost visibility in search results. Not only do they help search engines crawl the site, but they also let you communicate to the search engines what keywords you want a page to rank for.
Not to mention the benefits internal links bring to the end users!
A site audit tool typically assesses a number of issues with internal links. Clarity Audits, for example, will tell you:
- What pages have no internal links
- Which ones have too many of them
- Whether any of those links point to missing URLs
- And what other problems occur with those links (i.e., using relative reference.)

You can also crawl internal links to uncover any errors and quickly update across the site.
With such insight you can:
- Update any missing or broken internal URLs
- Replace broken links and improve crawlability
- Ensure links are transferring value between pages
- Improve site taxonomy and crawl budget use
Recommended Reading: The Ultimate Cheat Sheet on Internal Link Analysis for SEO
#6. Identifying Errors in Ajax or Heavy JavaScript
How to handle Ajax and JavaScript has changed rapidly over the years. In the past, Google embraced the usage of the "?escape_fragment_". Now, sites are reporting that pages are being de-indexed that are still utilizing the escape fragment on Ajax sites.
As more sites move to Ajax or heavy JavaScript, advanced technical practitioners must spot and identify errors as soon as possible.
As my colleague, Richard Chavez argued in an article about how to embrace JS in SEO:
If there’s one programming language you simply must embrace as an SEO, it’s JavaScript.”
An advanced audit software like Clarity Audits that can crawl Ajax and JS assists in diagnosing errors. Find out right away if your site is using pre-renders and, if so, add the pre-render URLs to perform site crawls.
This way, you can evaluate what issues exist on the render versus on-site.
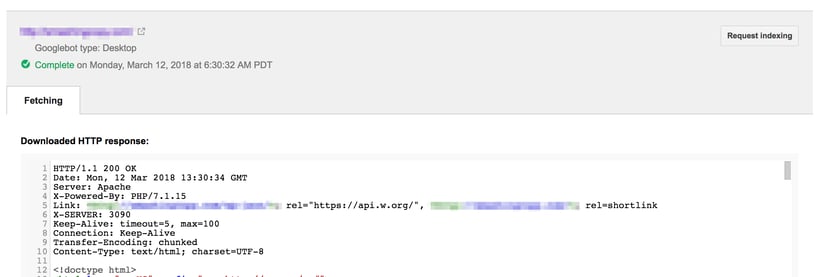
Similarly, users can utilize Fetch within the Google Search Console to analyze the code with JS rendered, exactly as the search engine would see it.
If there are components that are not appearing, then creating a crawl can help analyze why they are not appearing and uncover solutions.
#7. Incorporate New Techniques in Your Site Audits
The methods above are some of the most-used techniques reported by advanced technical practitioners, but there are always more methods to learn to provide a more robust ongoing Site Audit process.
This article provides additional techniques to better understand how to quickly identify errors and ongoing search visibility to know what issues to eliminate to maximize your potential within search engines.
These workflows also provide your customers with the best user experience possible when they visit your site.
If you have additional advanced technical SEO approaches or suggestions, please provide details in the comments below. We'd love to feature them in an upcoming post!
<<Editor's Note: this post was originally written in October 2018 and has since been updated.>>



2 Comments
Click here to read/write comments