
The robots.txt file serves as an initial checkpoint for search engine bots when they arrive at your website, providing them with instructions about which URLs they are prohibited from visiting.
However, if not used properly, this file can lead to significant technical SEO challenges.
That’s why it’s so important to be aware of what these mistakes are so that you can avoid them.
Key Takeaways
- Robots.txt directs crawler behavior, ensuring valuable pages are discovered efficiently and reliably.
- Misconfigurations can block critical content, disrupt indexing signals, and waste limited crawl resources.
- Continuous monitoring prevents accidental changes that quickly impact visibility across large, complex sites.
Here's what we'll cover in this post:
- What is a Robots.txt file?
- How Do Robots.txt Files Work?
- Why are Robots.txt files important?
- Common Mistakes With Robots.txt
What is a Robots.txt File?
The robots.txt file is a simple text file that is uploaded to the root of your domain (i.e. domain.com/robots.txt).It serves as the location that search engine bots and other spiders including AI/LLM crawlers automatically visit to check for specific rules about what they may or, more importantly, may NOT crawl.
All websites should have this file because, without it, search engines and AI crawlers will assume they can freely access the entire site without any restrictions.
How Do Robots.txt Files Work?
There are only two required commands for the robots.txt file:
- “User-agent:” - tells who the rules are for.
- “Disallow:” - which directories, files, or resources are forbidden.
There are also two optional commands:
- “Allow:” - exceptions to disallowed directories, files, or resources.
- “Sitemap:” - the URL location where the bots can find your XML sitemap or sitemap index.
The User-agent line(s) can specifically name the user-agents by the bot’s name (i.e. “Googlebot,” “Bingbot,”, “Google-Extended”, “GPTBot”) and provide specific instructions for each.
Here’s an example of a robots.txt providing instructions for Googlebot and Bingbot which blocks the crawling of a systems file directory.
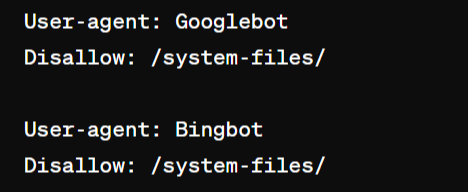
The user-agent line of the file can also provide general instructions to all bots by using a wild card “*” instead of providing unique instructions for each individual bot.
Here’s an example of a robots.txt providing instructions for all bots which does not block any resources:
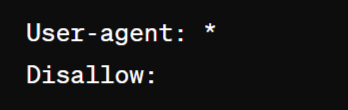
They can also block user agents like bots, spiders, and other crawlers from accessing your site’s pages.
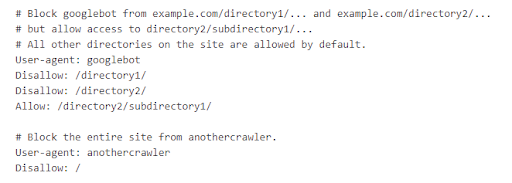
User-agents are listed in “groups." Each group can be designated within its own lines by crawler type indicating which files it can and cannot access.
We recommend collecting and reviewing all bot activity data to identify any additional bots, spiders, or crawlers that should be blocked from accessing your site’s content. seoClarity’s Bot Clarity can help with this.
Why are Robots.txt Files Important?
For enterprise sites, telling a crawler which pages to skip gives you greater control over your site’s crawl budget, freeing up more resources for your most important assets. Most small sites probably don’t need to restrict crawlers in any way.
Recommended Reading: Technical SEO: Best Practices to Prioritize Your SEO Tasks
20 Common Robots.txt Mistakes
Here are some of the most common mistakes with robots.txt that you should avoid making on your site.
1) Using Default CMS robots.txt Files
Many CMSs are overly aggressive when it comes to blocking files or resources that don’t need to be blocked or should be allowed.
Since every website is different, your robot.txt file should be customized by an experienced SEO who understands your site fully.
As such, you should avoid using default CMS robots.txt files.
2) Blocking Canonicalized URLs
Many webmasters and SEOs try to mitigate duplicate content by using canonical tags.
This is a common practice to control duplicate content caused by facets, filters, sort orders, custom parameters, personalization, and many other use cases.
However, if those URLs are blocked by robots.txt, search engines will not crawl the page to see the canonical tag.
3) Using Robots.txt to Noindex Pages
Using robots.txt to Noindex pages is an issue that frequently arises. But blocking URLs in robots.txt isn’t an instruction not to index them.
Google no longer adheres to noindex directives found in robots.txt files. If your robots.txt file predates this change or includes noindex commands, those pages may appear in Google's search listings.
The correct way to keep a page from being indexed is to use a page-level meta-robots noindex.
4) Blocking URLs that Are NOINDEX
Speaking of the NOINDEX directive, another common robots.txt mistake is blocking URLs that are NOINDEX.
A page-level meta-robots NOINDEX is a directive that will prevent URLs from being indexed.
BUT if those URLs are also blocked by robots.txt, they may remain indexed because search engines will not crawl the URLs to see the directive.
5) Case Sensitivity
Another common robots.txt issue to be aware of is using the wrong case.
It’s important to remember that the robots.txt file is case-sensitive.
For example, Disallow: /Folder will not block a folder named /folder.
As such, accidentally using the wrong case can result in content being crawled that was meant to be disallowed.
6) Blocking Essential Files
Google wants to see your content the same way an average human visitor sees your content. To do so, it needs access to image, Javascript, and CSS files.
As such, you should not block resources used to render your content.
For example - disallowing "/scripts/*" would block all JavaScript files if those files are in the /scripts/ folder.
7) Using robots.txt to “Hide” Sensitive or Private Content
Blocking crawlers via a robots.txt is not an effective way to hide content that should be private.
In fact, savvy users or competitors may look at the robots.txt file to find the location of such content.
While the noindex element mentioned will keep it from being indexed, password-protecting the content might be the best solution for restricting access.
8) Blocking Redirected URLs
Redirects are inevitable.
When consolidating URLs or migrating to a new website that requires 301 redirects, make sure the URLs being redirected aren’t blocked via robot.txt.
If they are, search engines won’t crawl the URL to honor the redirect, and your old URLs will remain indexed.
9) Unnecessary Trailing Slashes
Trailing slashes at the end of folders in your robots.txt can lead to unexpected blocking.
For example, disallowing "/contact/" might not block "/contact" as some search engine crawlers might interpret them differently.
10) Single File for Subdomains
Search engines treat subdomains like entirely separate websites. This means that having a single robots.txt file at the root of your main domain won't apply to subdomains.
As such, each subdomain needs its own robots.txt file to specify crawling instructions.
For example, let's say your main website is https://startupsavant.com/ and you have a subdomain for your blog at https://blog.sitebuilderreport.com/.
A robots.txt file at https://startupsavant.com/ won't affect how search engines crawl https://blog.sitebuilderreport.com/.
You'd need a separate robots.txt file on the blog subdomain to define crawling rules for those pages.
11) Using absolute URLs
While some people use absolute URLs to specify what to block or allow, we would recommend against this practice.
For example, disallowing access with "Disallow: https://domain.com/login" in the robots.txt file is incorrect. Search engines might misinterpret this or treat it as a command to block everything.
A better option would be to use a relative URL like "Disallow: /login".
12) Moving Staging or Development Site’s robots.txt to the Live Site
Many staging sites, if not password- or IP-protected, use a robots.txt file that blocks all bots from the entire site. Accidentally moving this file to the live or production site is a common accident that can lead to problems with the site being crawled properly.
If you used a disallow directive in the robots.txt file while your site was under construction, it’s essential to remove this disallow directive once the site officially goes live.
User-Agent: *
Disallow: /
seoClarity’s Page Change Monitor can be used to check for potentially devastating changes like this.
13) Moving Live Site robots.txt Files to Staging or Development Sites
This robots.txt issue is the opposite of #12 above.
If Staging or Dev sites are accessible to the public without password protection or only allowing accepted IPs, be sure to not use the same robots.txt file as the live site.
Note that blocking staging sites with robots.txt does not guarantee that it won’t get indexed. But using a robots.txt file allows crawlers full access and almost guarantees it will get indexed.
14) Empty User-agent
The user-agent string is a line in the robots.txt file that identifies the specific crawler or software making the request.
For example, "User-agent: Googlebot" indicates that the instructions following that line apply to the Google Search engine crawler.
As such, an empty user-agent in your robots.txt file can cause confusion for search engine crawlers and potentially result in your crawl instructions not being applied correctly.
15) Blocking Removed Pages
If you’ve removed (404 or 410) URLs for any reason, Google needs to be able to crawl the page to see that it returns a 404 or 410 code.
As such, you should not block pages that you have removed from your website.
16) Improper Use of Wildcards
Google and other search engines support the “*” and “$” characters as wildcards to control and customize parsing in your robots.txt file.
Using these characters in the wrong place can cause important URLs to get blocked or allow URLs to be crawled that you don’t wish to be crawled.
Follow Google’s guidelines on how they interpret wildcards.
17) Blocking pages with HREFLANG
If your robots.txt file is blocking URLs that have Hreflang tags for alternate language pages, Google will not crawl those pages to see the Hreflang URLs.
As such, you should avoid blocking pages with Hreglang tags to ensure that Google understands the language and regional targeting of your content. This is crucial for serving the right content to the right audience, especially in international SEO contexts.
Recommended Reading: Why the Hreflang Tag is Essential to Global SEO
18) Using the "crawl-delay" Directive
Currently, Google only supports user-agent, disallow, allow, and sitemap elements.
Although you may see sites that use the crawl-delay" directive in robots.txt, it is ultimately an unofficial and inconsistently supported instruction for search engines. At this time, Bingbot does honor the crawl-delay setting.
Instead, their mechanisms for regulating crawl speed are based on various factors like server load and website size.
For this reason, including a crawl-delay directive in your robots.txt file is essentially ignored by Googlebot.
19) Comments Misuse
Comments in robots.txt can be helpful for documenting your crawl instructions. But accidentally including the comments in the instructions can lead to unexpected behavior and potentially prevent search engines from understanding your preferences.
Robots.txt uses a specific format with directives and user-agent lines. Comments, typically starting with "#" (hash symbol), are meant for human readers and are ignored by search engines.
Placing comments in the wrong location (like in the example below) can lead to unintended consequences.
User-agent: Googlebot
# Disallow: /login (This line is commented out)
Disallow: /images/
20) No Sitemap Reference
While this is not necessarily an error, failing to include a Sitemap directive in the robots.txt file may be a missed opportunity.
This is because the robots.txt file is the first place search engines look when it crawls your website. If you’ve submitted your XML sitemap through Bing Webmaster Tools or Google Search Console, this may not be necessary. But It gives secondary or smaller search engines an easy way to discover the main pages of your site.
Note: While most still consider including an XML sitemap in your robots.txt file a best practice (it’s still suggested as optional in Google Search Central), it may also make it easier for competitors or nefarious organizations to scrape your site as you make the location of your XML sitemap public.
How to Monitor Robots.txt Issues
There are two main ways to identify and stay on top of any robots.txt issues that may occur. These include:
- Use Google Search Console and the URL Inspection Tool to see if there are any issues.
- Run consistent crawls using an SEO site audit technology like seoClarity’s to check for robots.txt issues (and other technical SEO issues) at scale.
Conclusion:
To ensure that your website follows all best practices for robots.txt files, review your site for the common mistakes that we’ve listed above.
When making alterations to your website, always benchmark its performance prior to and after changes. Our Client Success Managers are happy to assist you in creating these benchmark reports.
If you need additional assistance, our Professional Services team is also available to help diagnose any errors, provide you with an implementation checklist and further recommendations, or assist with QA testing.
<<Editor's Note: This piece was originally published in April 2020 and has since been updated.>>




1 Comment
Click here to read/write comments