SEO Crawl Budgets:
Monitoring, Optimizing, and Staying Ahead

So far, we’ve considered the crawl budget from your point of view - a website owner or marketer, tasked with increasing search visibility. But the budget affects the search engine in many regards too.
According to Google’s own Gary Illyes, for Googlebot, the crawl budget is comprised of two elements:
Leaving its technical aspects aside, crawling a site works quite similarly to having it visited by a human user.
Googlebot requests access to various assets - pages, images or other files on the server - similar to how a web browser does when operated by a user.
As a result, crawling uses up server resources and bandwidth limits allocated to the website by its host.
Too much crawling, therefore, can have a similar effect as suddenly having bouts of visitors landing on your site at once. Simply put: it can break the site, slowing down its performance or overloading it completely.
Crawl rate prevents the bot from making too many requests too often and disrupting your site’s performance.
Now, Google lets webmasters decide their site's crawl rate through Google Search Console.
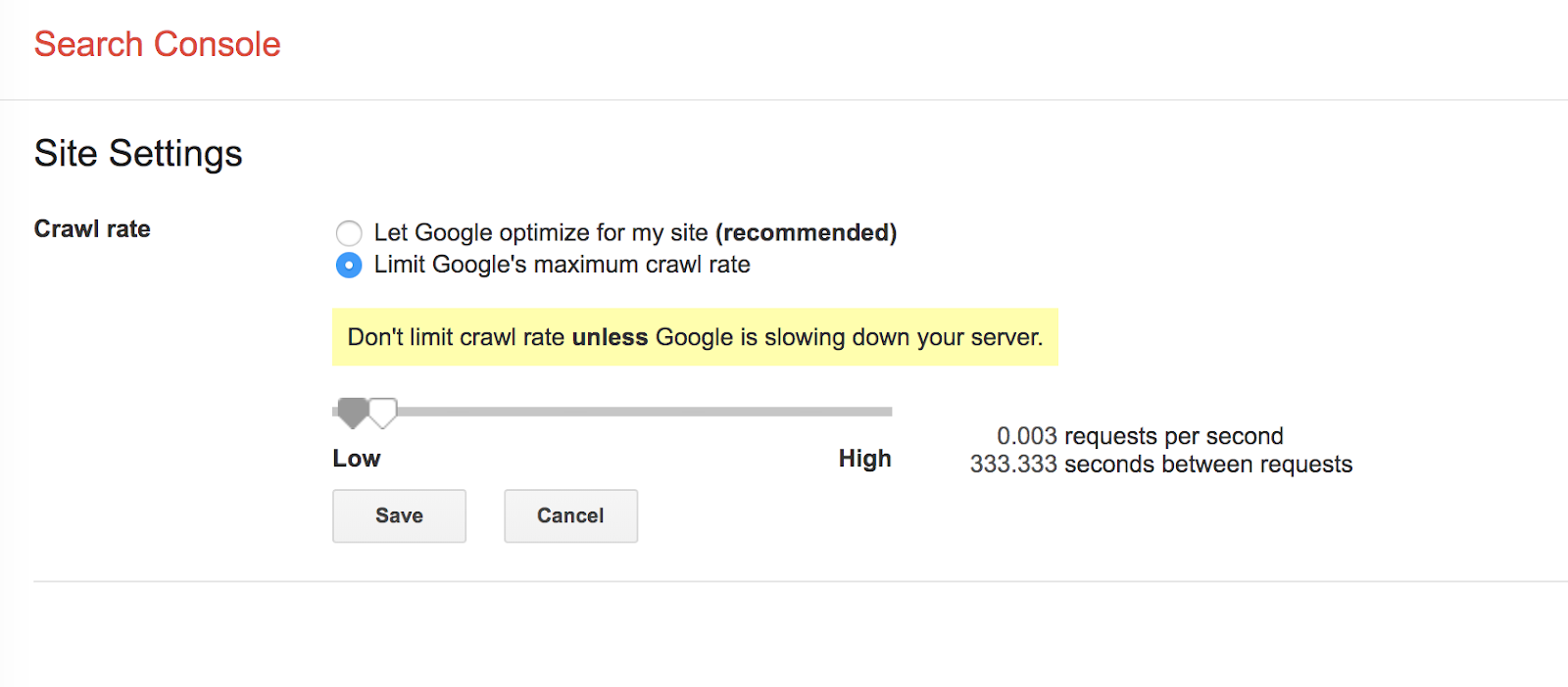
With this functionality, the company can suggest to the crawler at what rate it should access the site.
Unfortunately, there are drawbacks to doing so manually. Setting the rate too low will affect the frequency at which Google discovers your new content, and setting it too high can overload the server.
In fact, the site might suffer from two issues:
Unless you’re absolutely sure, we recommend leaving the process of optimizing the crawl rate to Google. Instead, focus on ensuring that the crawler can access all critical content within the available crawl budget.
If there’s no demand from indexing, there will be low activity from Googlebot, regardless of if the crawl rate limit isn’t reached. Crawl demand helps crawlers determine whether it's worth accessing the website again.
There are two factors that affect the crawl demand:

The goal here is to have your site crawled properly without creating potential issues that would negatively impact user experience.
According to Google, the biggest issue that affects crawl budget is low-value URLs.
Having too many URLs that present little or no value, yet are still on the crawler’s path, will use up the available budget and prevent Googlebot from accessing more important assets.
The problem is that you might not even realize that you have many low-value URLs as many are created without your direct impact. Let’s see how that typically happens.
Faceted navigation refers to different ways users can filter or sort results on a web page based on different criteria. For example, any time you use Ross-Simons’ filters to fine-tune the product listing, you use faceted navigation.
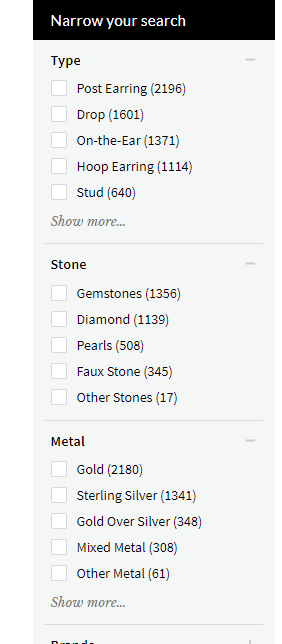
Although helpful for users, faceted navigation can create issues for search engines.
Filters often create dynamic URLs which, to Googlebot, might look like individual URLs to crawl and index. This can use up your crawl budget and create a lot of duplicate content issues on the site.
Faceted navigation can also dilute the link equity on the page, passing it to dynamic URLs that you don’t want indexed.
There are ways to overcome this:
Add a “nofollow” tag to any faceted navigation link.
This will minimize the crawler’s discovery of unnecessary URLs and therefore reduce the potentially explosive crawl space that can occur with faceted navigation.
Add a “noindex” tag to inform bots of which pages are not to be included in the index.
This will remove pages from the index, but there will still be crawl budget wasted and link equity that is diluted.
Use a robots.txt disallow. For URLs with unnecessary parameters, include a directory that will be robots.txt disallowed. This lets all search engines freely crawl URLs that you want a bot to crawl.
For example: we could disallow prices under $100 in the robots file.
Disallow: *?prefn1=priceRank&prefv1=%240%20-%20%24100
Canonical tags allow you to instruct Google that a group of pages have a preferred version. Link equity can be consolidated into the chosen preferred page utilizing this method. However, the crawl budget will still be wasted.
Similarly, URL parameters - like session IDs or tracking IDs - or forms sending information with the GET method will create many unique instances of the same URL.
Those dynamic URLs, in turn, can cause duplicate content issues on the site and use up much of the crawl budget, even though none of those assets are, in fact, unique.
A "soft 404" occurs when a web server responds with a 200 OK HTTP status code, rather than the 404 Not Found, even though the page doesn’t exist.
In this case, the Googlebot will attempt to crawl the page, using up the allocated budget, instead of moving on to actual, existing URLs.
Unfortunately, pages that have been hacked can increase the list of URLs a crawler might attempt to access. If your site got hacked, remove those pages from the site and serve Googlebot with a 404 Not Found response code.
Seeing hacked pages isn’t anything new to Google and the search engine will drop them from the index promptly, but only if you serve it a 404.
Infinite spaces are near-endless lists of URLs that Googlebot will attempt to crawl.
Infinite spaces can occur in many ways - but the most common include auto-generated URLs by the site search.
Some sites list on-site searches on pages which leads to the creation of an almost infinite number of low-value URLs that Google will consider crawling.
Another common scenario is displaying a calendar on a page with a “next month” link. Each URL will have this link, meaning that the calendar can generate thousands of unnecessary infinite spaces.
 Google has suggested methods to deal with infinite spaces, such as eliminating the entire categories of those links in the robots.txt file. Doing so will restrict Googlebot from accessing those URLs from the start and save your crawl budget for other pages.
Google has suggested methods to deal with infinite spaces, such as eliminating the entire categories of those links in the robots.txt file. Doing so will restrict Googlebot from accessing those URLs from the start and save your crawl budget for other pages.
A broken link is a link that points to a page that does not exist. It may happen because the wrong URL in the link or the page has been removed but the internal link pointing to it has remained.
The broken and redirected link points to a non-existing page with a redirect, often in a series of redirect jumps.
Both issues can affect crawl budget, particularly the redirected link. It can send the crawler through a redirect chain, using up the available budget on unnecessary redirect jumps.
To learn more about URL redirects, visit our guide: A Technical SEO Guide to URL Redirects.
Site speed matters for the crawl budget too. If the load time is too long when Googlebot tries to access a page, it might give up and move to another website altogether.
A response time of two seconds results in a greatly reduced crawl budget on the site and you'll likely see the following message:
"We’re seeing an extremely high response-time for requests made to your site (at times, over 2 seconds to fetch a single URL). This has resulted in us severely limiting the number of URLs we’ll crawl from your site, and you’re seeing that in Fetch as Google as well."
Alternate URLs defined with the Hreflang tag can also use up the crawl budget.
Google will crawl them for a simple reason: the search engine needs to ensure that those assets are identical or similar, and are not redirecting to spam or other content.
In addition to HTML content, CSS or JavaScript files also consume crawl budget. Years ago, Google wasn’t crawling these files, so it wasn’t that big of an issue.
But since Google started crawling these files (especially for rendering pages for things like where the ads appear on the page, what is above the fold, and what might be hidden) many people still haven’t put time into optimizing them.
The XML sitemap plays a critical role in optimizing the crawl budget. For one, Google will prioritize crawling URLs that are included in the sitemap over the ones it discovers when crawling the site.
But that doesn’t mean that you should add all pages to the sitemap. Doing so will result in Google prioritizing all content, and wasting your crawl budget on accessing unnecessary assets.
More and more websites launch AMP versions of their content. In May 2018, there were over 6 billion AMP pages on the web and the number has certainly grown significantly since then.
Google has confirmed already that AMP pages consume crawl budgets too since Googlebot has to crawl those assets as well.
It does so to validate the page for errors and to ensure that the content is the same between the regular page and its AMP counterpart.
An important aspect of optimizing your crawl budget is monitoring how Googlebot visits your site and how it accesses the content.
There are three ways to do it, two of which lie within GSC:
Google Search Console includes a breadth of information about your site’s stance in the index and the search performance. It also provides certain insight into your crawl budget.
First of all, in the Legacy tools section, you’ll find the Crawl Stats report, showing Googlebot activity on your site within the last 90 days.
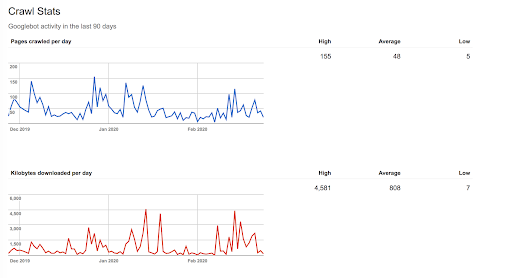
From the report you can see that, on average, Google crawls 48 pages a day on this site. Assuming that this rate remains consistent, you can calculate the average crawl budget for the site with this formula:
Average pages per day * 30 days = Crawl Budget
In this case, it looks like this:
48 pages per day * 30 days = 1440 pages per month.
Naturally, this is a crude estimate but it can give some insight into your available crawl budget.
Note: Optimizing the crawl budget using the tips above should increase the number.
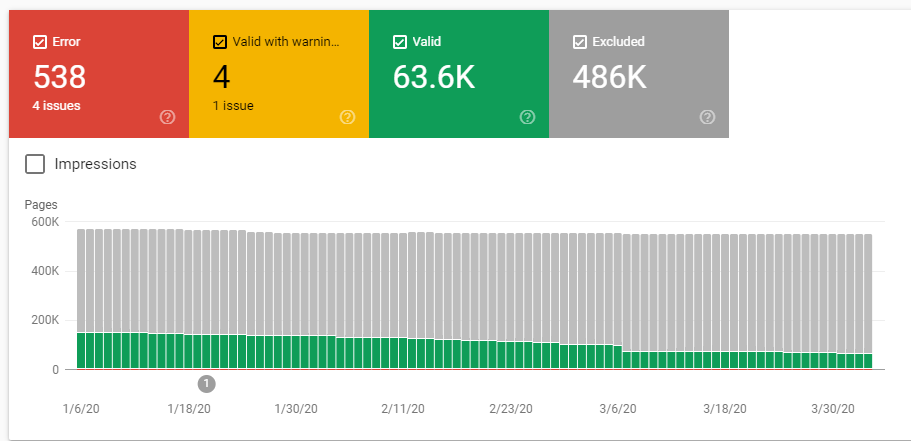
The Coverage Report in GSC will also show how many pages Google has indexed on the site and excluded from indexation. You can compare that number with the actual volume of content assets to identify if there are any pages the Googlebot has missed.
Without a doubt, the server log file is one of the biggest sources of truth about a site’s crawl budget.
This is because the server log file will tell you exactly when search engine bots are visiting your site. The file will also reveal what pages they visit the most often, and the size of those crawled files.
11.222.333.44 - - [11/Mar/2020:11:01:28 –0600] “GET https://www.seoclarity.net/blog/keyword-research HTTP/1.1” 200 182 “-” “Mozilla/5.0 Chrome/60.0.3112.113”
On Mar 11, 2020 someone using Google Chrome tried to load https://www.seoclarity.net/blog/keyword-research. The “200” means the server found the file, weighing in at 182 bytes.
Now, it's true that server log-file analysis is not a simple task. You have to go through thousands of rows of server requests to identify the right bot and analyze its activity.
At seoClarity, you have access to Bot Clarity, our site audit tool that, among other functionalities, provides a detailed log-file analysis.
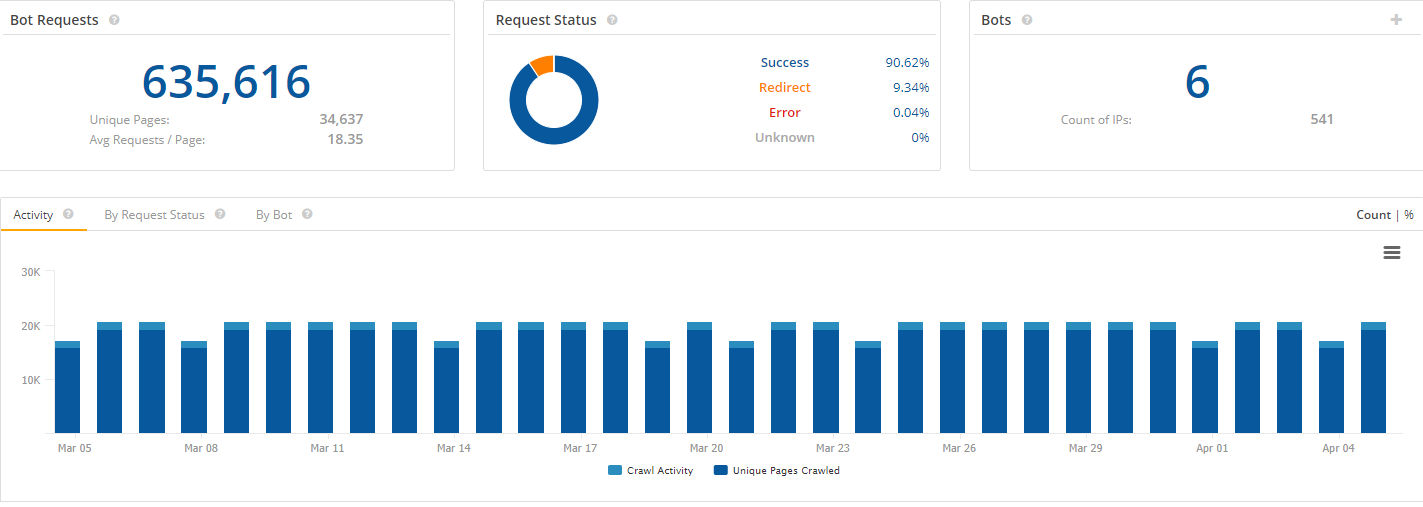
With Bot Clarity, you can:
