
Despite the massive size of Google’s index (revealed at 400 billion docs and counting), the rising volume of AI-generated content has caused it to face limitations.
This means that fewer pages on your site may actually make it onto Google’s SERPs for people to find organically.
To ensure your most important pages get indexed by search engines, it’s more important now than ever for SEOs to focus on increasing the crawl efficiency of their website.
In this post, we’ll show you how to make it happen. We’ll discuss the idea of crawl depth and go over strategies that increase the likelihood that even your less popular pages get indexed.
But first, let’s do a quick recap on how Google crawls and indexes enterprise sites.
Key Takeaways
- Pages with more links are crawled more frequently.
- The bigger the page’s depth, the lower its chance of being crawled within the site’s crawl budget.
- To increase the crawl frequency of less authoritative and relevant pages, improve the site’s architecture, update the sitemap regularly, and speed up the site.
Table of Contents:
- How Content Ends Up in SERPs
- What is Crawl Depth?
- What is Crawl Prioritization?
- 4 Ways to Increase Your Site's Crawl Efficiency
How Content Ends Up in SERPs
The search engine’s process of finding and including web pages in SERPs consists of four steps:
- Crawl, in which search engine bots go through a website to discover its content. Typically, they do so by following internal links, but crawlers can also use the sitemap for this purpose.
- Render, at which stage, the crawler renders each page to identify and analyze its content. This step is all about learning what a page is about and evaluating its content (among other things) to determine its quality and authority.
- Index, when the search engine includes (or updates) the information about those pages in its index.
- Rank, which is all about associating the page in a relevant position for a specific query in the Google search results.

Of the entire process, in this post, we’re concerned with the first step: crawl.
Because unless the search engine can access, discover, and crawl a website’s assets, its ability to rank for relevant keywords will be severely impacted.
However, ensuring the crawlability of the site is just the first step.
Another SEO issue to consider is getting the crawler to regularly visit less popular content within a site’s crawl budget as well, and that’s where the issue of crawl depth comes in.
What is Crawl Depth?
The term crawl depth refers to how many pages search engine bots will access and index on a site during a single crawl.
Sites with high crawl depth see many of their pages crawled and indexed. Those with a low crawl depth would, typically, have many of their pages not crawled for long periods.
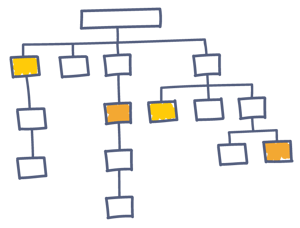 Crawl depth relates to the site’s architecture. If you consider the most common website structure, with the homepage at the top of the hierarchy and inner pages linked from it in tiers, then the crawl depth defines how deep into those tiers the crawler will go.
Crawl depth relates to the site’s architecture. If you consider the most common website structure, with the homepage at the top of the hierarchy and inner pages linked from it in tiers, then the crawl depth defines how deep into those tiers the crawler will go.
Recommended Reading: The Best Two Website Taxonomy Methods to Boost SEO
The Difference Between Crawl Depth and Page Depth
Crawl depth is often confused with page depth, but the two aren’t the same.
The term page depth defines how many clicks a user needs to reach a specific page from the homepage — using the shortest path, of course.
Using the graph above as an example, the homepage is at depth 0, right there at the top.
Pages right below it would be on depth 1, those right below, depth 2, and so on. This is how it's reflected in our Clarity UI. So, pages linked directly to the homepage are closer to the top of the site architecture.
As a rule, pages on depth 3 and lower will, generally, perform poorer in the organic search results. This is because the search engines may have issues reaching and crawling them, within the site’s allocated crawl budget.
This brings us to another important topic: crawl prioritization.
What is Crawl Prioritization?
Crawl prioritization is the process search engines use to decide which pages to crawl first, and how frequently, based on their perceived value, relevance, and freshness.
In practice, this means crawlers allocate more of their limited crawl budget to pages that:
- Contain valuable updated content
- Earn strong internal or external signals (links, authority, engagement)
- Are essential for user experience (e.g., key category pages, high-performing templates)
- Are frequently updated or mission-critical for search visibility
By ensuring your most important pages are crawled and indexed sooner, crawl prioritization helps search engines keep your content fresh in the index, improves your ability to rank, and prevents low-value or duplicate URLs from consuming crawl resources that could be better spent elsewhere.
Recommended Reading: Homepage SEO: How to Get It Right, Finally
4 Ways to Increase Your Site's Crawl Efficiency
Improving overall crawl efficiency requires a closer look at the technical and structural elements that guide how search engines move through your site.
The following four approaches highlight the most impactful ways to help crawlers access, understand, and index your content more effectively, ensuring your most valuable updated pages get the attention they deserve.
1. Optimize Your Internal Linking Structure
First, optimize your internal linking structure. Reduce the number of clicks required to reach pages you want to have crawled more often.
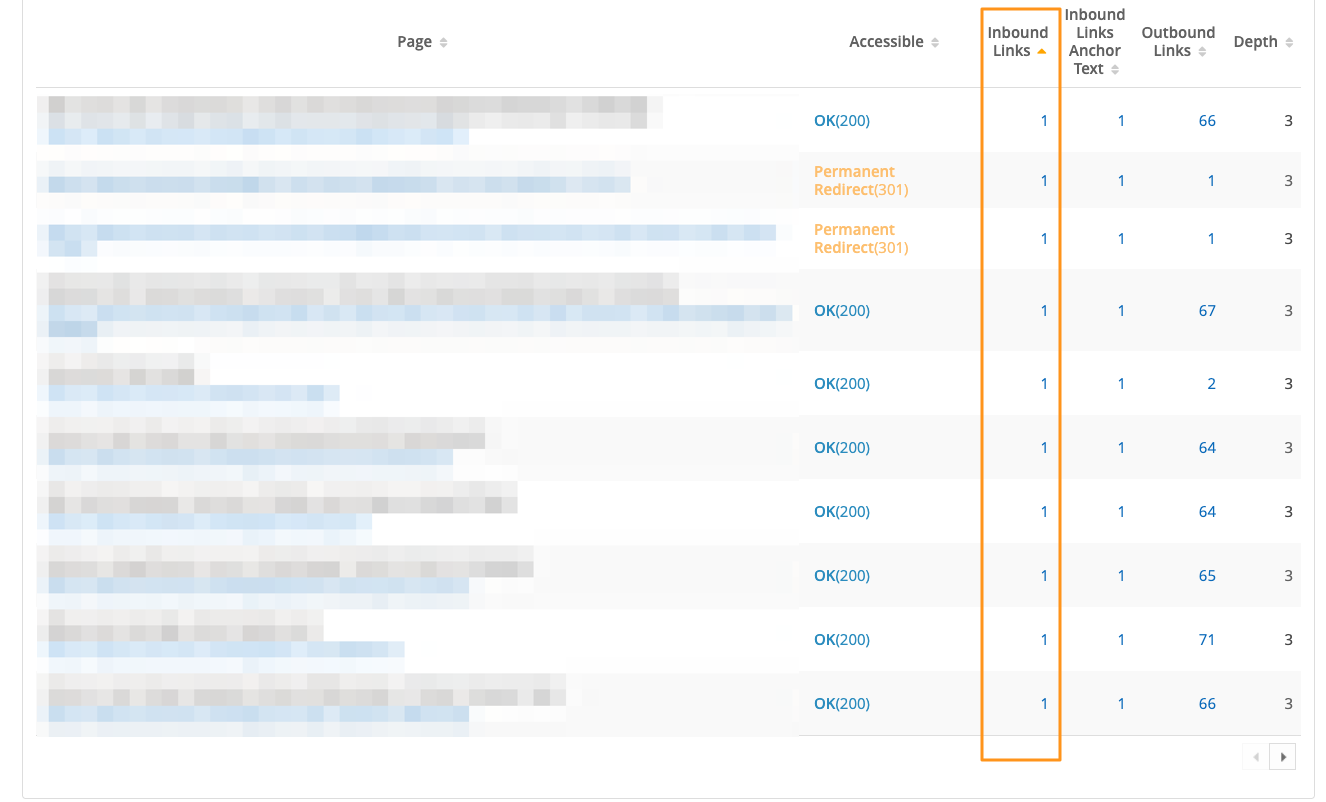
Identify opportunities to link to target pages from popular content as well. Using seoClarity’s Internal Link Analysis feature, evaluate the current links to the page. The screenshot below shows the analysis for pages in depth 3.
Note that all of those assets have only one internal link pointing to them, suggesting an opportunity to bring them higher in the site’s hierarchy with some clever tactics.
Also, use categories and tags, if possible in your CMS, to provide the additional structure a crawler could follow to discover this content.
2. Update Your Sitemap Regularly
Create and update the XML sitemap often — this acts as a directory of sorts that includes the list of all URLs you want the search engine to index, along with information about when a page has been updated last.
As a rule, search engines will crawl URLs in the sitemap more often than others, so, by keeping the sitemap fresh, you increase the chances for those target pages to get crawled.
Note: seoClarity's built-in site crawler allows you to create a sitemap based on the information it collects.
3. Improve Site Speed to Increase Crawl Coverage
Finally, increase page speed. A fast site will reduce the time required for crawlers to access and render pages, resulting in more assets being accessed during the crawl budget.
(A quick note: seoClarity runs page speed analysis based on Lighthouse data to deliver the most relevant insights to drive your strategies.)
4. Find and Fix Broken Links
Broken links can significantly impede the crawl efficiency of your website by leading search engine bots into a dead end, wasting their valuable time and resources that could have been spent indexing valuable content.
This not only hinders the discovery of new and updated pages but also negatively impacts your website's overall SEO health, as it signals poor site maintenance and lowers user experience quality.
Fixing these links ensures that search engines can effectively navigate and index your site's content, which in turn helps maintain your site's visibility and ranking in search engine results pages (SERPs).
Learn how to find and fix broken internal links at scale here.
<<This post was originally published in June 2020 and has since been updated.>>




Comments
Currently, there are no comments. Be the first to post one!