
Gathering, isolating and extracting elements from the HTML on your site is very useful for a variety of SEO related activities.
Instead of analyzing and extracting content one page at a time, most enterprise SEOs may prefer to do it in bulk for either a particular subset of pages or for their entire site.
Scraping or extracting data from your site for audits, analysis, content updates, and resolution of issues can all be made easy by combining XPath with a content extraction tool like seoClarity’s site crawler.
Knowing the basics of XPath is a powerful tool especially if you are in my shoes. I work with clients often to set-up and extract data using XPath.
The most common requests range from extracting content from a specific div, auditing video or image links, checking schema, or any of the other SEO related elements on a page that need to be verified.
How is Web Scraping Useful in SEO?
There is never a one size fits all approach to how a webpage or a website is built. Developers use best or common practices and write the code to have beautiful websites render to pages the entire world uses to digest content.
There may be instances where you need to audit elements that exist in a particular section of a page, or check data within a particular schema.
Most site crawlers follow standard functionality to scrape the most often used or analyzed elements of your site. They are not designed to work for a custom or specific request unless you can specify how to query your site to get the data you need.
Recommended Reading: Don’t Be Tongue-Tied: Learn RegEx Patterns for SEO
This is where XPath is very useful. It allows you to specify how to search your site to locate the element you need to view within the extraction tool or custom site crawler. Some people prefer to use regex or regular expressions for this.
If you are looking to extract content from HTML, XPath is the preferred choice since it has been designed for querying. It may be possible to use regex instead of XPath in some instances, but there will be cases where it will fail.
What is XPath?
XPath or XML Path is a querying language that can be used to find nodes in XML (Extensible Markup Language) documents.
Since HTML and XML are both markup languages that follow similar structure and format rules, XPath can also be used to query HTML documents.
This means, in plain terms, we can use XPath to search and process items in HTML documents by using a specific syntax to follow a page’s structure or hierarchy.
Types of XPath
There are two types of XPath: absolute and relative.
Absolute XPath:
It uses the complete XPath from the root HTML tag to the specific element. This is not recommended as it would fail if there are any changes made in the path of the element.
A key characteristic of Absolute XPath is that it starts with a single forward slash (/) which signifies the root node.
For Example:
I have the text “technical seo” on a page that is hyperlinked.

This is its Absolute XPath:
/HTML[1]/body[1]/div[5]/div[1]/div[3]/div[1]/div[1]/div[1]/div[1]/div[2]/span[1]/div[4]/div[1]/div[1]/div[1]/div[1]/div[2]/p[2]/a[1]
Relative XPath:
A relative XPath starts from the node of your choice which does not have to be the root node.
It starts with a double forward slash (//) and the advantage to using this is that you do not need to mention the long XPath.
For the same example above, the Relative XPath would be:
//a[contains(text(),'technical SEO')]
As you can see, it is a lot shorter and simpler querying via Relative XPath instead of Absolute XPath.
Basic Syntax for XPath
Here’s a quick cheat sheet of XPath expressions:
|
Expression |
What it means |
|
/ |
This selects the root node. |
|
// |
This selects nodes in the document from the current node that match the selection no matter where they are |
|
. |
This selects the current node. |
|
.. |
This selects the parent of the current node. |
|
@ |
This selects attributes. |
|
This would select all attributes named href or in the case of HTML; all href links on a page. |
Predicates
Predicates help you restrict selected nodes in a node set based on some condition. Here are some basic ones:
|
Path |
What it does |
|
//a[1] |
This selects the first element that is a child of <a> |
|
//a[last()] |
This selects the last element # last <a> |
|
//a[@foo] |
This selects all the <a> elements that have a foo attribute |
|
//a[@foo='bar'] |
Selects all the <a> elements that have a foo attribute with a value of ‘bar’ |
Here’s a full list of the XPath expressions and predicates for your reference.
Examples of Using XPath to Extract Content
Let’s dive into some examples where we use the knowledge about the basics of XPath gained above to locate specific elements within the HTML of a page.
Video or Image Link Extraction
Extracting of YouTube links within a div is a common request for SEOs that work on sites that have video links that need updating or auditing for relevance.
For example: If this is the code on your site:
<div class="video">
<iframe src="https://www.youtube.com/embed/ABCDEFG"></iframe>
And you want to extract the video links that are contained within the div class: “video”. This is the XPath you would use:
//div[class=”video”]/iframe/@src
Another common request is to extract the image links within a specific div on a page.
For example, if this HTML was on your site:
<img class="image" src="https://www.myimagelocation/imagefilename.png" alt="" title="" data-element="desktop_image" style="max-width: 100%; height: auto;">
This is the XPath you would use to locate the src of the image:
//img[@class="image"]/@src
Scraping Open Graph and Twitter Markup
Social Media is gaining importance and relevance with SEOs. There are specific meta tags that are designed to convey data about your site to Social Media sites when pages to your website are shared.
These meta tags are called Open Graph Meta Tags. The most popular social media sites to use this are Facebook and LinkedIn.
In the same vein, the social media network Twitter looks at Twitter cards to gather information about your site.
Most of the modern site crawlers like seoClarity’s own crawler extract and store this information by default. But it's also possible to query and scrape the same data from your site using XPath.
For example, for the below Open Graph markup and Twitter markups:

This is the XPath you would use to extract the description and title for OpenGraph and Twitter markups:
//meta[@property="og: description"]/@content
//meta[@property="og: title"]/@content
//meta[@name="twitter:description"]/@content
//meta[@name="twitter:title"]/@content
XPath Expressions Cheat Sheet for Common SEO Elements
|
Scraping <h3> |
//h3 |
|
Scraping Hreflang Attribute |
//link[@rel=’alternate’]/@hreflang |
|
Scraping Hreflang URL |
//link[@rel=’alternate’]/@href |
|
Scraping Canonical URL |
//link[@rel=’canonical’]/@href |
|
Scraping AMP |
//link[@rel=’ampHTML’]/@href |
|
Scraping Viewport |
//meta[@name=’viewport’]@content |
If you are looking for an easier way to get the XPath of an element, there are plenty of turnkey Chrome Extensions available that help you get the XPath of web elements.
Using seoClarity to Pull Content
A big advantage with using seoClarity‘s site audit technology and built-in crawler is that it can be used as a link extraction and audit tool.
Once you set up extraction of additional content on a crawl you can scrape selected data elements from your entire site.
Recommended Reading: Finding Additional Content: Narrow in on Specific Site Features
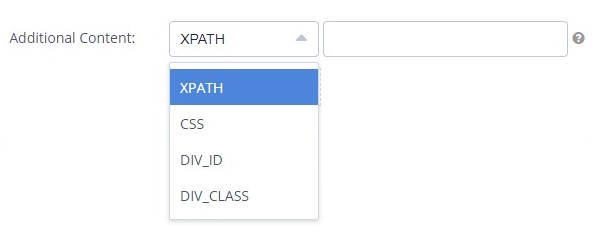
The XPath knowledge learned above can be used to plug into the Additional Content Section of Clarity Audits to extract the custom data you need.
In addition to XPath, we also have the option to collect CSS, DIV_ID and DIV_CLASS. Enter it directly in the UI to extract the content and links.
Final Thoughts
XPath can be like a magic trick up an SEOs sleeve. It is akin to learning a new language and may be difficult to start. But once you get the hang of it, it can be extremely useful specially when dealing with searching HTML.
Just like XPath is useful for querying, regular expressions or regex is the tool to know when it comes to identifying words and numbers.
In the world of SEO, it has many uses, but it is most often used to segment keywords and URLs. In my next article, I will cover the basics of regex and how it can be useful in SEO.



Comments
Currently, there are no comments. Be the first to post one!