
Enterprise sites can have thousands or even millions of pages — it’s no surprise that it’s extremely challenging to find specific instances of content or links from your pages.
Yet, there are so many real-world circumstances where the ability to locate and extract content from your site (at scale) proves to be invaluable.
The Challenge With Data Extraction
Without the proper technology to assist you, the process of locating content and links would be an entirely manual process: You would have to manually spot-check each page to verify that changes have been successfully implemented and are live on your site.
This, of course, is not at scale, and the amount of work required would mean that you’re always behind.
It’s like trying to find a digital needle in a haystack, fruitlessly searching pages and source code for the content that you’re looking for.
Why Data Extraction is Important
Crawling for additional content on your site allows for three main outcomes, you can:
- Identify and audit where certain site elements exist,
- Find something outdated that needs to be changed, or
- Locate an element that should be removed from your site entirely.
I’d like to show you the use cases that we see with our enterprise clients and how they leverage the power of Clarity Audits — our crawler and site audit technology.
These enterprise SEOs use big data to work intelligently, at scale.
Extract Internal Links That Contain a Specific PDF
There are some cases when using a PDF format on your site content makes sense: PDFs are a good format to use so users can download content or forms, or when you want to make sure that the content is non-editable.
There are times when you need to locate and audit all PDFs on your site, or find a specific PDF.
Why would you want to do this? Just like any piece of content, PDFs are not immune to decay and may need to be audited and updated to a new PDF link entirely.
Within Clarity Audits and Additional Content in the seoClarity platform, you can easily find all PDFs on your site with this XPath:
//a[substring(@href, string-length(@href) - string-length('.pdf') +1) = '.pdf']/@href
This XPath looks for all href attributes in the <a> elements of a page that pertain to a PDF.
If you enter this in the Additional Content section while you set-up a crawl, our built-in crawler will find all instances of a PDF for each page in the crawl.
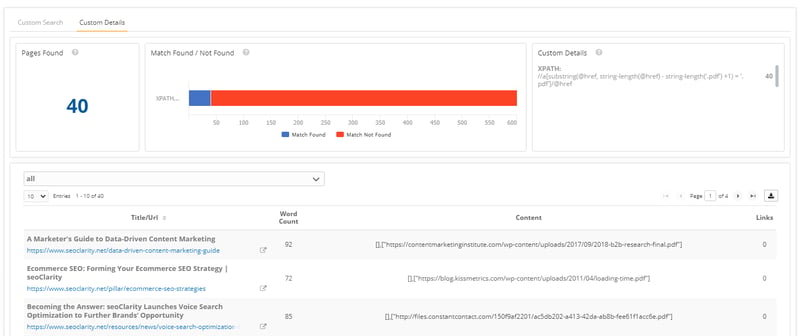
(Clarity Audits discovering PDFs on a site.)
In the image above from Clarity Audits, you can see that in this crawl, we found 40 pages that contained a PDF. In the table, you can see the list of pages and the PDF link that was captured.
Recommended Reading: Extracting Additional Content Using XPath for SEO
Search/Match Pages That Contain a Specific Link
One of the most common use cases of Additional Content is to find specific links on your site. You may need to replace the link to lead to a new resource, or look for an obsolete link — there are many scenarios that this use case applies to.
Here’s an example of what the XPath for this might look like:
//a[contains(@href,'https://www.example.com/example.html')]/..
In this example, the XPath matches all <a> elements of the page where the href attribute contains “https://www.example.com/example.html”.
With the above logic, you can find any type of content on your site. The example link above can be replaced to match a specific PDF link or video link (or any kind of link you need to locate for that matter).
Clarity Audits then allows you to find all pages that contain instances of the specific link that you set out to discover.
Extract Links and Content From a Specific Section of Templated Pages
Another common use case is to capture and view all content and links from within a Div or a CSS.
For example, if you work on an ecommerce site and have made changes to the description of your product items, you’ll need to extract and audit those at scale. In most cases, the description is part of a Div.
Use Clarity Audits to enter the Div ID, Div Class or CSS — we then extract all the content and links from within the Div or CSS and present it in our easy-to-view UI so you can audit at scale.
If your site uses templates (Div) you can seamlessly grab all the information from the Div. All the raw data that exists in that Div (i.e. the content) will be pulled for the audit.
This allows you to confirm that any site changes have made their way onto the site successfully, instead of having to manually verify changes.
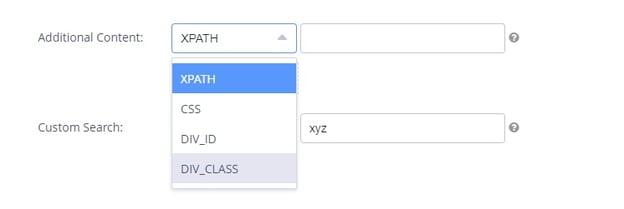 (There are a number of ways to search for content on your site.)
(There are a number of ways to search for content on your site.)
Find Instances of a Word in a Crawl
Clarity Audits has another feature that is very useful when auditing for instances of a specific word on your site.
This is called Custom Search, which makes it possible to find the count of occurrences of the appearance of a word in the source of a page — this goes farther than the actual on-page content. Clarity Audits searches of all instances of the word found in the Source Code.
If, for example, you’re a product supply company who no longer sells a certain product, you would need to remove that product from your site. The crawler allows you to locate all instances where that word appears.
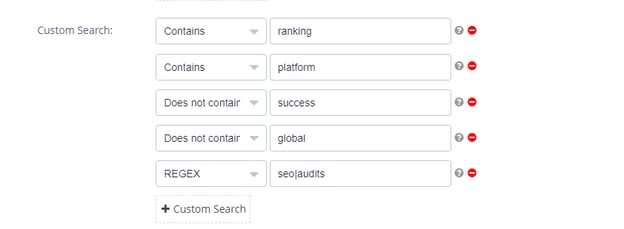
(Setting Custom Search parameters in Clarity Audits.)
This image shows a crawl setup, and highlights the flexibility that Clarity Audits allows for when searching content.
In a single crawl you can search for pages that “contain” or “do not contain” a specific string. You can even leverage the power of RegEx to add flexibility to your search.
The results look like this:
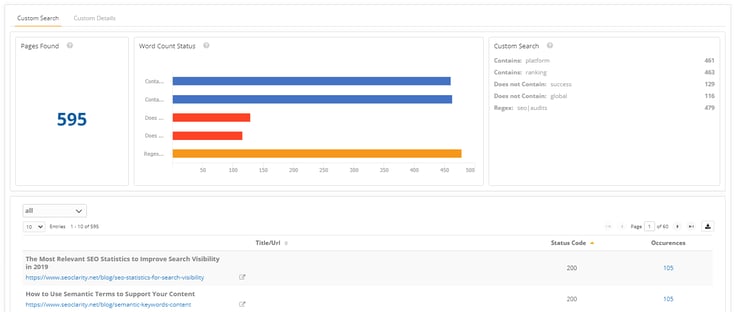
(Results for a Custom Search.)
In this image of our platform, you see the summary chart that shows you the number of pages that match the search criteria, the number of pages found that match for specific criteria, and then a list of everything searched for.
The table shows you the details of the pages that match the search, the status code and the occurrences of the search criteria on the page. Click on the count of occurrences to see the number of instances each of the search criteria show up on the page.
Recommended Reading: Don't Be Tongue-Tied: Learn RegEx Patterns for SEO
Summary
The flexibility of Clarity Audits allows you to locate a variety of content and links from your site, all at incredible scale.
Using the power of XPath and Regex, and the capabilities of Clarity Audits, you can tailor the crawl to locate and capture any specific content or element.




Comments
Currently, there are no comments. Be the first to post one!