
Crawl budget isn’t something we SEOs think about very often. And, if you aren't familiar with the term "crawl budget", it doesn't mean money available. This term focuses on the ability to optimize the way Google reads a site. The goal is to ensure your site is the easiest to crawl and that your most valuable pages are crawled frequently.
At the same time, we want Google to index at least our most valuable pages, right? For one, that’s the prerequisite for being included in the search results. But also, as we’ve discovered, the content that hasn’t been crawled for a long time receives materially less traffic. It's worth mentioning that Google determines the order of URL's to crawl and it all depends on the authority of the page.
But the thing is – to ensure that crawlers access your pages, you need to prepare your site to make the most out of your available crawl budget.
Here are five strategies to help you do just that.
#1: Identify and Remove Potential Roadblocks
Broken links, 404s, erroneous htaccess and robots files, and long redirect chains will prevent bots from indexing pages on your site.
- Broken links and 404s will stop the bots in their tracks.
- A faulty line of code in .htaccess or robots.txt files can prevent them from accessing entire sections on the site.
- Bots typically stop following long redirect chains at some point, and that’s typically before they reach the final page in the redirect chain.
But here’s the problem – when you manage a website with thousands of content assets, you may not even know that any of these problems exist. And even if you suspect a problem, you have no way of guessing where they are.
Here’s how to find out:
Step 1. Use a crawler – like seoClarity's built-in crawler – to execute a site audit to identify broken links and 404 pages.
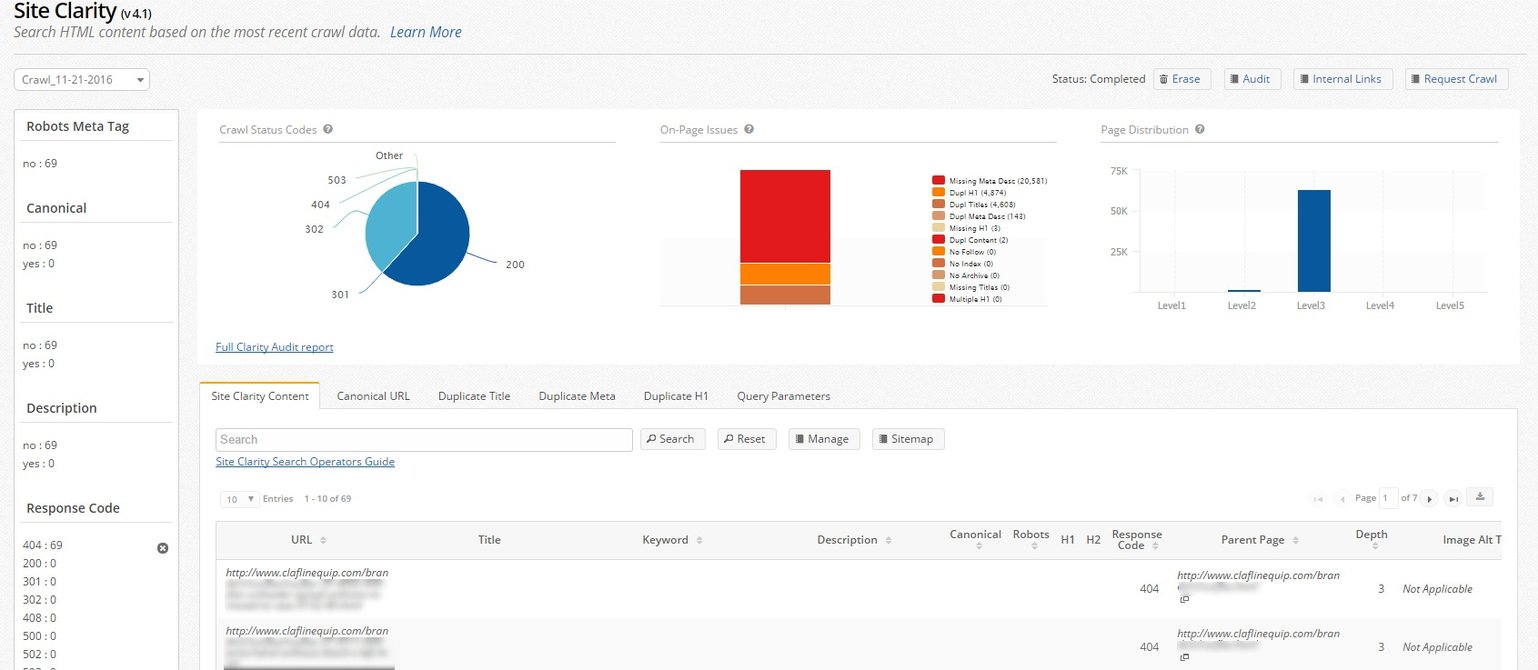
Step 2. Check for too many redirect chains.
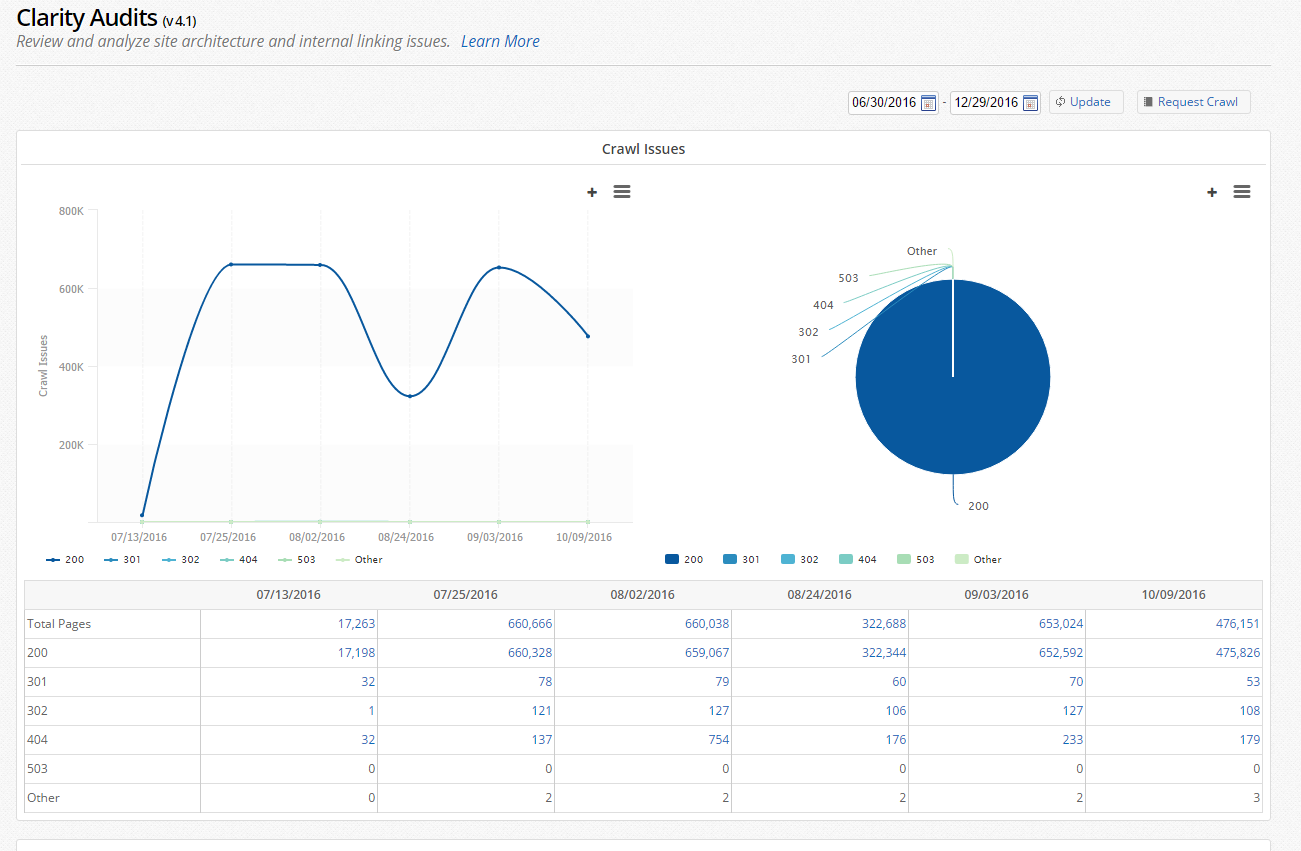
Step 3. Use Robots.txt Tester App to validate the file
Head to SEOBook’s Robot.txt Analyzer, enter the URL of your file and a list of URLs or site sections you want to test the file against. The tool will report what spiders are allowed in the file per section.
Recommended Reading: How to Find (and Fix) Crawlability Issues to Improve Your SEO
#2. Optimize Crawl Parameters on Dynamic URLs
Here’s a serious problem with crawlers – they tend to see dynamic URLs as separate pages, even though they in fact point to the same content.
And as you know, too many dynamic URLs may burn your crawl budget, without getting many other pages indexed.
Luckily, fixing this problem is actually quite easy:
- Log in to Google Search Console,
- Open the Crawl Section, then click URL Parameters
- Specify parameters your content platform adds to URLs to let Googlebot know about them.

#3. Regularly Clean Up Your Sitemap
A sitemap makes your content just so much more organized. And that’s not just for users. Bots can travel via links in the sitemap too. In fact, when validating your sitemap, Google makes it clear that it uses it later for Googlebots to crawl.
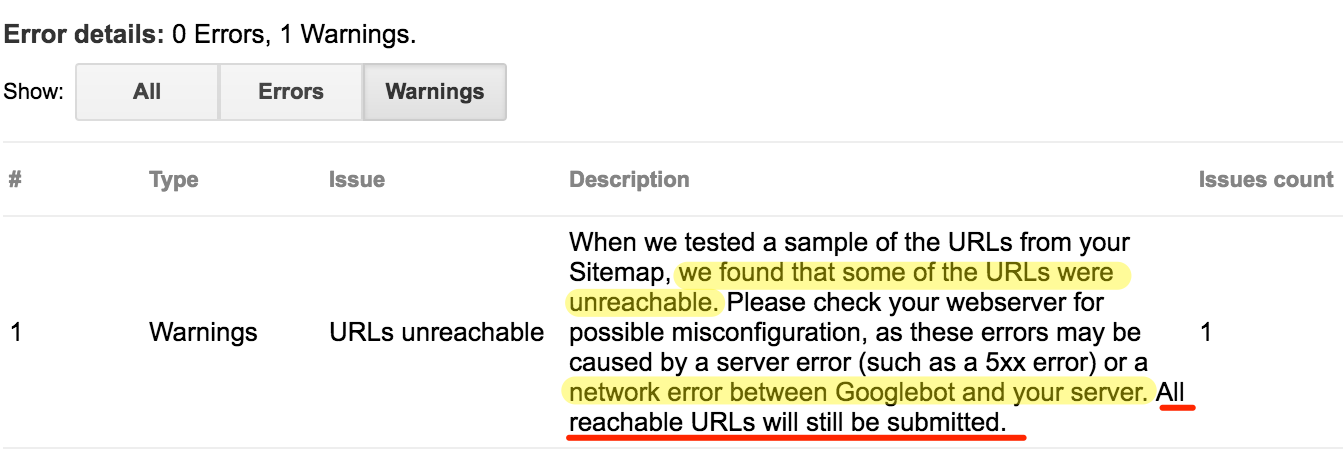
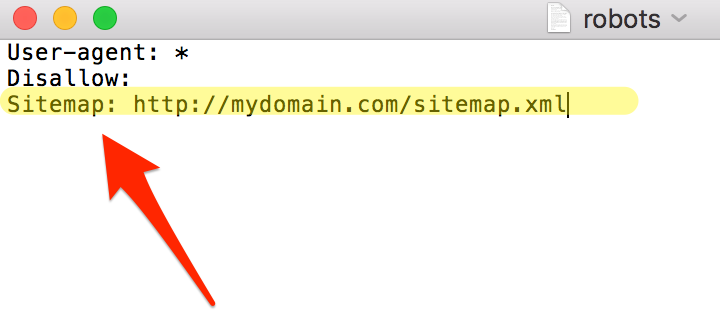
But at the same time, Googlebots can also get stopped in their tracks by broken links, missing pages, and other roadblocks. For that reason, regularly update and clean up your sitemap from any clutter that might obstruct the bot on their way through the site. Ideally, make sure that your sitemap includes only the most relevant URLs you want Googlebots to visit, and remove anything you don’t want the bot to see. As the last step, include the path to the sitemap in your robots.txt file. As the file is one of the first places a crawler will look, pointing to the sitemap will increase your chances that it will start the crawl from there.
#4. Improve Internal Linking
In my in-depth piece on interlinking posted earlier this year, I wrote: “Regardless of how much you may have tried to tame it, interlinking eventually gets out of control.” Just like some content types, for example, blog articles or news, tend to attract a lot of internal links naturally, many important pages get ignored, resulting in missing the opportunity to point Googlebots to them.
Also, a solid website architecture will naturally make it simpler for the bots to discover content assets on your site. Although reworking the entire taxonomy will most likely be out of question, work on improving interlinking, particularly between pages you absolutely want crawlers to visit.
#5. Block Sections You Don’t Want Crawlers to Visit
Finally, since a crawler will visit only a certain amount of pages on your site during each visit, it makes sense to block sections you don’t need them to visit to save the crawl budget.
As Joost de Valk points:
“One of the common problems we see on larger eCommerce sites is when they have a gazillion way to filter products. Every filter might add new URLs for Google. In cases like these, you really want to make sure that you're letting Google spider only one or two of those filters and not all of them.”
To block them, disallow sections you don’t need Googlebot to see in the robots.txt file. It’s that simple, but it will have a significant effect on your site’s crawlability.
Let’s face it, crawl budget isn’t something we SEOs think about very often. At the same time, having the content regularly crawled is the prerequisite for being included in the search results and to maintain rankings.



Comments
Currently, there are no comments. Be the first to post one!