The way that you structure your URL and links within your site is absolutely essential to the function of your site. This is important to ensure your site can be successfully crawled and indexed appropriately.
The structure of your URL is the web address to your site and its subpages. It’s the way Google, Bing, and other search engines crawl and index your domain name. No matter what, you do not want any redundant URLs or links that are broken on your website.
You have two basic choices when it comes to the selection of URLs: absolute URL and relative URL. If you choose the wrong type, it will not only make the site difficult for search engines to crawl but could also affect your SEO strategy.
In this article, we address the following:
What are Absolute URLs?
An absolute URL contains the entire address from the protocol (HTTPS) to the domain name (www.example.com) and includes the location within your website in your folder system (/foldernameA or /foldernameB) names within the URL.
Basically, it's the full URL of the page that you link to.
An example of an absolute URL is:
<a href = http://www.example.com/xyz.html>
What are Relative URLs?
The relative URL, on the other hand, does not use the full web address and only contains the location following the domain. It assumes that the link you add is on the same site and is part of the same root domain.
The relative path starts with the forward slash and leads the browser to stay within the current site.
An example of a relative URL is:
<a href = "/xyz.html">
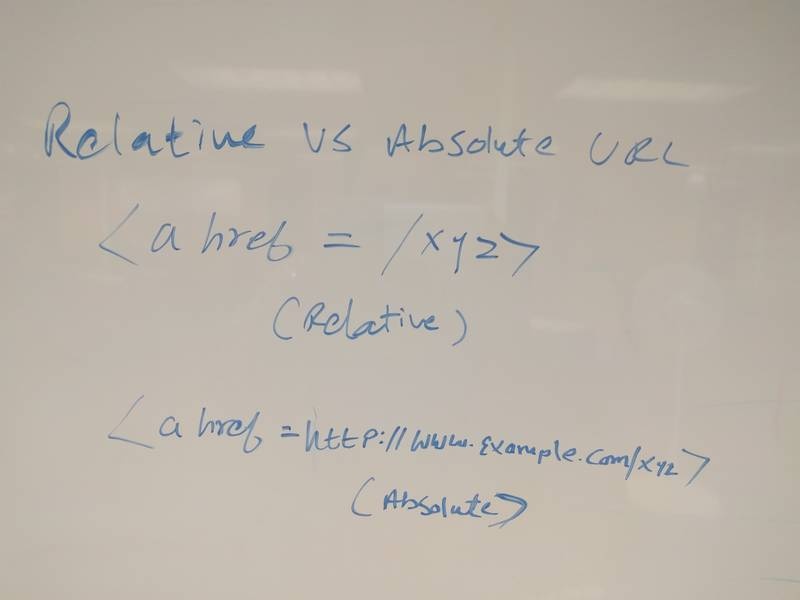
(More of a visual learner? The above is a helpful sketch of the differences between relative and absolute URLs.)
Why Choose Relative URLs?
Quicker Coding
Large websites are made much easier to code when you shorten your URL into a relative format.
Staging Environment
If you are using a content management system that has staging environment with its own unique domain like WordPress or SharePoint, then your entire website is replicated on that staging domain.
The relative format allows the same website to exist on staging and production domain, or the live accessible version of your website, without having to go back in and re-code all of the URLs. This not only makes coding easier for a web developer but also serves as a time saver.
Faster Load Times
Pages that use relative URLs will load more quickly than pages that use absolute URLs, for the most part, although the difference is minuscule at best.
Why Choose Absolute URLs?
Foils Scrapers
For URLs using the absolute method, it's harder for people to scrape information from your site directory using scraper programs. If you have all of your internal links as relative URLs, it would be very easy for a scraper to simply scrape your entire website and put it up on a new domain.
Disallows Duplicate Content
It's very important to use absolute URLs in order to avoid duplicate content issues. Imagine you have multiple versions of root domains that are indexed in Google without a canonical tag that points to the correct version of the site.
For example:
- http://www.example.com
- http://example.com
- https://www.example.com
- https://example.com
Recommended Reading: 301 Redirects vs. Rel=Canonical Tags: The Best Route for Duplicate Content
According to Google, these are four different sites and Google could potentially enter your site on any one of these four pages. At this point, if all of the internal links are relative URLs, they can then crawl and index your entire site using whatever format — this eventually results in a duplicate content issue.
Improve Internal Link Strategy
While coding your URLs, you do want to think about internal linking. If you have a <base href> tag that was implemented wrong on the site along with relative URLs, it will create a page that will land on a 404 error page.
For example, on your category page http://www.example.com/category/xyz.html, you have base href tag that reads:
<base href="http://www.example.com/category/xyz.html"/> and relative URLs internal link (/category/abc.html).
When Google crawls your internal links, it will result in 404 error page as shown below.
http://www.example.com/category/xyz.html/category/abc.html
With the use of absolute links, you are avoiding this type of situation.
Helps With Crawling
Google crawlers follow the internal links on your pages to crawl more deep pages on your site. There is a limited number of URLs that Google crawlers crawl due to the actual cost involved in it.
Based on this fact, if you have a million pages on your site and during the crawl Google frequently comes across issues, then it would be more logical for Googlebot to leave your site.
They prefer to spend their time on sites that are well optimized.
This situation can be avoided by using the absolute URL to help Google streamline the crawling process, which will not only save time, but it also encourages it to come back more often and crawl more pages.
Recommendation on Using Absolute vs. Relative Links
If you use relative path or the absolute path, there are pros and cons to each option. Make sure that you pick the appropriate strategy according to your SEO needs.
There is no default, so the choice is yours, but for the most part the absolute URL approach is recommended, as it definitely has more pros than cons and will help improve your site's SEO.
However, there are times when relative URLs will be the better option — depending on the need of your site.
Need to update your relative links to absolute links at scale?
Try our SEO Execution Platform >
Editor's Note: This post was originally published in January 2018 and has been updated for accuracy and comprehensiveness.